Implement DP Resilience with AWS S3
In this guide, you will learn how to configure Data Plane (DP) resilience in API7 Enterprise using AWS S3 or S3-compatible storage as the external configuration storage. For AWS S3, API7 supports two methods for authenticating gateway nodes:
- IAM Roles for Service Accounts (IRSA) – Uses a Kubernetes service account associated with an IAM role to grant gateway pods secure access without static credentials.
- IAM User and Access Key – Uses the IAM user and access key for authentication.
Both methods allow gateway nodes to fetch configuration and continue serving traffic when the Control Plane (CP) is unavailable. For S3-compatible storage such as MinIO, Ceph, or Alibaba Cloud OSS, use the provider's access key and secret key, and configure the custom endpoint.
Use IAM Roles for Service Accounts (IRSA)
This method leverages a Kubernetes service account associated with an IAM role to allow API7 gateway pods to securely access AWS S3 without embedding static credentials.
Prepare AWS Resources
You will prepare the following resources on AWS:
- An Amazon EKS cluster to deploy API7 gateway instances.
- An IAM OIDC provider for the cluster.
- Two S3 buckets:
- One bucket for dynamic configuration of the gateway group, such as keyring and discovery data.
- One bucket for gateway resource configuration, such as routes and services.
- An IAM policy that grants read and write access to the two S3 buckets.
- An IAM role with the above policy attached, mapped to the Kubernetes service account.
EKS Cluster
Create an Amazon EKS cluster if one is not already available.
For detailed instructions, see the official AWS documentation Get started with Amazon EKS.
IAM OIDC Provider for Cluster
Enable an IAM OIDC identity provider for the EKS cluster. This is required to use IAM Roles for Service Accounts (IRSA), which allows Kubernetes workloads to securely access AWS services such as Amazon S3 without embedding long-term credentials.
For detailed instructions, see the official AWS documentation Create an IAM OIDC provider for your cluster.
S3 Buckets
Create two S3 buckets (the bucket names below are examples):
fallback-cp-data- used to back up the dynamic configuration of the gateway group, such as keyring and discovery data.fallback-cp-config- used to back up gateway resource configuration, such as routes and services.
The bucket names will be referenced later in gateway deployments.
For detailed instructions on creating S3 buckets, see the official AWS documentation Create a general purpose bucket.
IAM Role and Kubernetes Service Account
To allow gateway pods to access the S3 buckets securely, follow the official AWS documentation Assign IAM roles to Kubernetes service accounts to:
-
Create an IAM policy that allows read and write access to the two S3 buckets.
{"Version": "2012-10-17","Statement": [{"Sid": "FallbackCP_S3Access","Effect": "Allow","Action": ["s3:PutObject","s3:GetObject"],"Resource": ["arn:aws:s3:::fallback-cp-config","arn:aws:s3:::fallback-cp-data","arn:aws:s3:::fallback-cp-config/*","arn:aws:s3:::fallback-cp-data/*"]}]} -
Create an IAM role and attach the previously created IAM policy.
-
Create a Kubernetes service account and associate the IAM role with it.
Ensure that the IAM role is associated with a Kubernetes service account in the same namespace where the gateway instances are deployed.
This maps an IAM role with S3 permissions to a Kubernetes service account used by the gateway pods, enabling them to access S3 without embedding AWS credentials.
Deploy a Backup Gateway Node
In the API7 Dashboard, navigate to Gateway Instances > Add Gateway Instance. Switch to the Kubernetes tab and fill in the following details before the deployment script generation:
- Customize the Helm release name.
- Specify the namespace where the gateway will be deployed.
- Specify the Kubernetes service account that is annotated with the IAM role granting permission to read from and write to the S3 buckets.
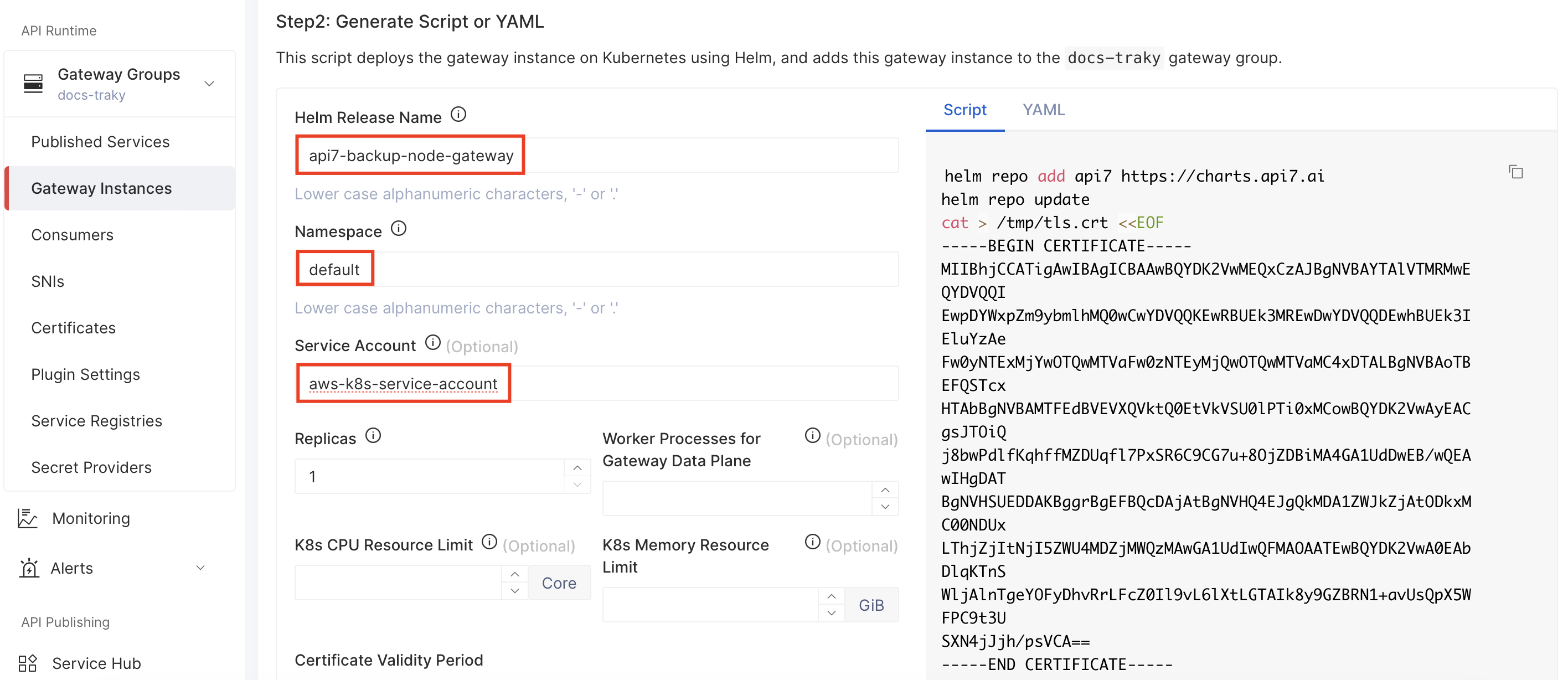
Click Generate to generate the deployment script. You should see the service account name has already been set in the helm upgrade command. Next, manually add the highlighted --set flags below to the helm upgrade command:
helm upgrade --install -n default --create-namespace api7-backup-gateway-node api7/gateway \
--set ... \ # other parameters
--set "serviceAccount.name=aws-k8s-service-account" \
--set "deployment.fallback_cp.interval=60" \
--set "deployment.fallback_cp.mode=write" \
--set "deployment.fallback_cp.aws_s3.region=ap-southeast-2" \
--set "deployment.fallback_cp.aws_s3.resource_bucket=fallback-cp-data" \
--set "deployment.fallback_cp.aws_s3.config_bucket=fallback-cp-config"
❶ Configure the time interval of configuration backup in seconds.
❷ Configure the gateway in backup write mode, allowing it to periodically export CP-derived configuration to external storage.
❸ Specify the AWS region.
❹ Specify the S3 buckets that store resource and config data.
For a Helm deployment that uses S3-compatible storage, configure provider-specific credentials and add the endpoint flag:
--set "deployment.fallback_cp.aws_s3.endpoint=https://s3-compatible.example.com"
Connect to your EKS cluster and run the updated deployment script to deploy the backup gateway node.
Examine the pod status and logs to ensure that there are no errors related to connectivity with S3 buckets.
Verify
In this section, you will verify that configuration data is successfully backed up to Amazon S3 and that traffic gateway nodes can continue operating using the fallback configuration when the Control Plane is unavailable.
Review Data Backup in S3
In the AWS Console, navigate to your S3 buckets. Verify that data is being written to both the fallback-cp-data and fallback-cp-config buckets.
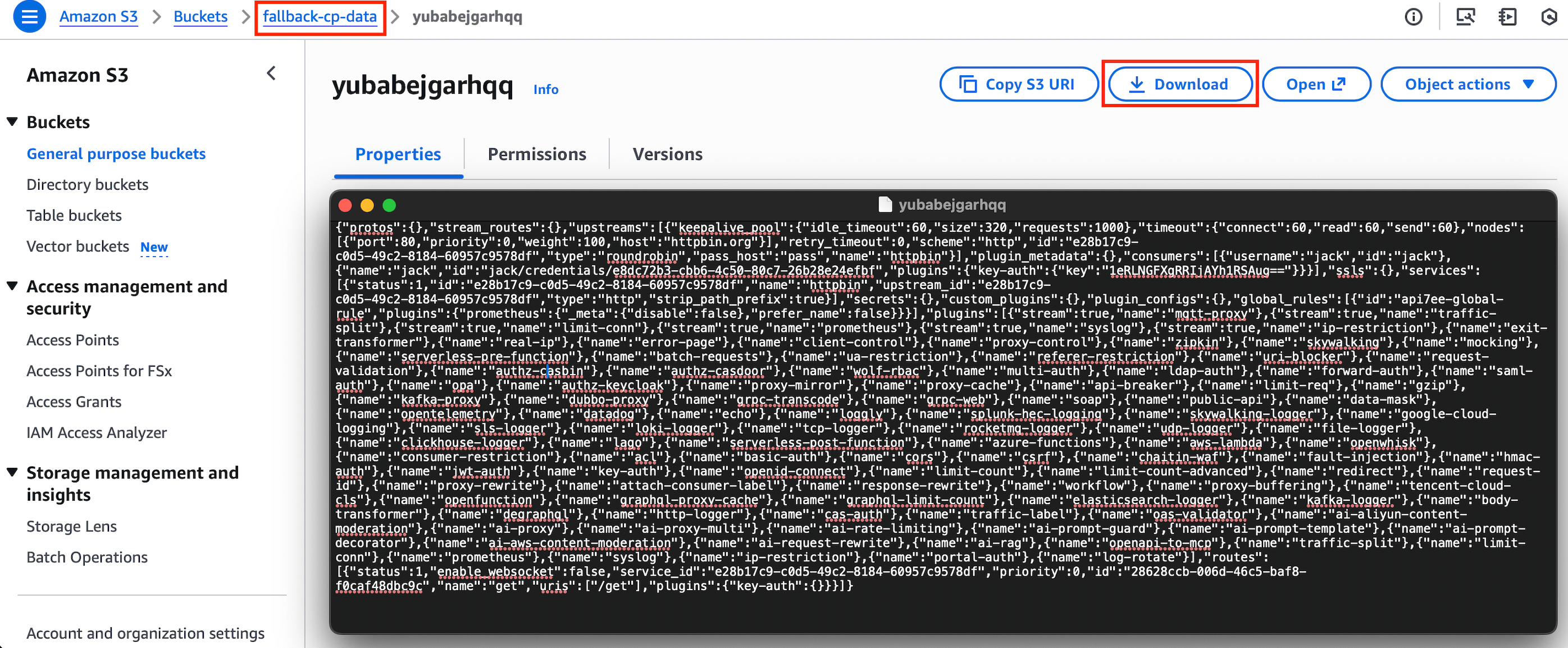
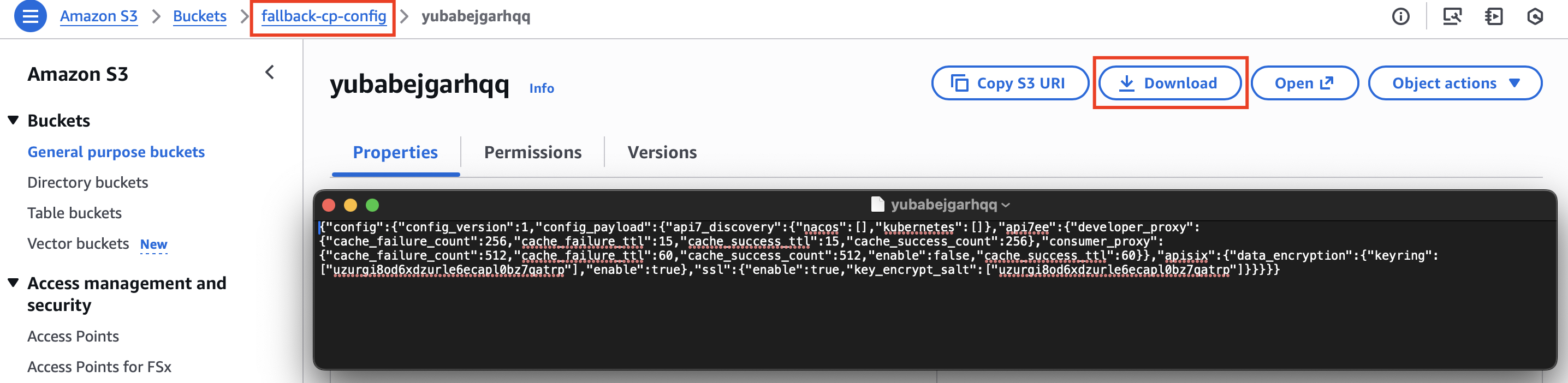
You should see configuration files periodically updated by the backup gateway node, indicating that CP-derived configuration is being successfully backed up.
Ensure Traffic Gateway Nodes Use Fallback Configuration
Suppose the Control Plane (CP) becomes unavailable and you need to configure Data Plane (DP) traffic nodes to fetch configuration from external storage.
Whether you are updating existing traffic gateway nodes or starting new ones, generate the deployment script from the API7 Dashboard and manually apply the following highlighted --set flags in the helm upgrade command.
helm upgrade --install -n default --create-namespace api7-traffic-gateway-node api7/gateway \
--set ... \ # other parameters
--set "etcd.host[0]=https://INVALID_DOMAIN:7943" \
--set "serviceAccount.name=aws-k8s-service-account" \
--set "deployment.fallback_cp.aws_s3.region=ap-southeast-2" \
--set "deployment.fallback_cp.aws_s3.resource_bucket=fallback-cp-data" \
--set "deployment.fallback_cp.aws_s3.config_bucket=fallback-cp-config"
❶ Simulate Control Plane unavailability by setting an invalid ETCD host.
❷ Specify the Kubernetes service account. Update with your service account name.
❸ Specify the AWS region.
❹ Specify the S3 buckets that store resource and config data.
For a Helm deployment that uses S3-compatible storage, configure provider-specific credentials and add the endpoint flag:
--set "deployment.fallback_cp.aws_s3.endpoint=https://s3-compatible.example.com"
Connect to your EKS cluster and run the updated deployment script to deploy or upgrade the traffic gateway node. The node should now operate based on the configuration stored in AWS S3 buckets.
To verify the setup, send requests to your gateway. The responses should reflect the configuration previously defined in the CP, including any routes, services, or plugins you have configured.
This confirms that the traffic gateway node is correctly using the fallback configuration and can continue serving traffic even when the CP is unavailable.
Use IAM User and Access Key
This method uses the IAM user and access key to authenticate gateway pods. It requires managing static credentials.
Prepare AWS Resources
Follow the linked documentation to create and configure the necessary AWS resources:
- Create two S3 buckets (the bucket names below are examples):
fallback-cp-data: to store dynamic gateway configuration, such as keyring and discovery data.fallback-cp-config: to store gateway resource configuration, such as routes and services.
- Select an existing IAM user or create a new one for the integration, and obtain its access key and secret access key.
- Attach an IAM policy granting read and write access to the S3 buckets to the IAM user.
For S3-compatible storage, prepare equivalent bucket permissions, access credentials, and the custom endpoint URL from your storage provider.
Deploy a Backup Gateway Node
- Docker
In the API7 Dashboard, navigate to Gateway Instances > Add Gateway Instance. Switch to the Docker tab, fill in a name for the backup gateway node, and click Generate to generate the deployment script.
In the running gateway, add the fallback_cp configuration to the gateway's configuration file:
deployment:
fallback_cp:
interval: 60
mode: "write"
aws_s3:
access_key: your-aws-iam-access-key
secret_key: your-aws-iam-secret-access-key
region: ap-southeast-2
config_bucket: fallback-cp-config
resource_bucket: fallback-cp-data
❶ Configure the time interval of configuration backup in seconds.
❷ Configure the gateway in backup write mode, allowing it to periodically export CP-derived configuration to external storage.
❸ Replace with your AWS IAM user access key and secret access key.
❹ Replace with your AWS region.
❺ Replace with your S3 buckets that store resource and config data.
For S3-compatible storage, add the custom endpoint to the aws_s3 block:
deployment:
fallback_cp:
aws_s3:
endpoint: https://s3-compatible.example.com
Reload the gateway instance for configuration changes to take effect. Examine the gateway logs to ensure that there are no errors related to connectivity with S3 buckets.
The gateway should start running as a backup node and pushing configurations to the S3 buckets regularly.
Verify
In this section, you will verify that configuration data is successfully backed up to Amazon S3 and that traffic gateway nodes can continue operating using the fallback configuration when the Control Plane is unavailable.
Review Data Backup in S3
In the AWS Console, navigate to your S3 buckets. Verify that data is being written to both the fallback-cp-data and fallback-cp-config buckets.
You should see configuration files periodically updated by the backup gateway node, indicating that CP-derived configuration is being successfully backed up.
Ensure Traffic Gateway Nodes Use Fallback Configuration
Suppose the Control Plane (CP) becomes unavailable and you need to configure Data Plane (DP) traffic nodes to fetch configuration from external storage.
- Docker
Whether you are updating existing traffic gateway nodes or starting new ones, in the running traffic gateway nodes, add the fallback_cp configuration to the gateway's configuration file:
deployment:
role: data_plane
role_data_plane:
config_provider: json
fallback_cp:
aws_s3:
access_key: your-aws-iam-access-key
secret_key: your-aws-iam-secret-access-key
region: ap-southeast-2
config_bucket: fallback-cp-config
resource_bucket: fallback-cp-data
❶ Configure the gateway to run in standalone mode.
❷ Replace with your AWS IAM user access key and secret access key.
❸ Replace with your AWS region.
❹ Replace with your S3 buckets that store resource and config data.
For S3-compatible storage, add the custom endpoint to the aws_s3 block:
deployment:
fallback_cp:
aws_s3:
endpoint: https://s3-compatible.example.com
Reload the gateway instances for configuration changes to take effect. The gateways should start running in standalone mode and fetching configurations from S3 buckets.
To verify the setup, send requests to your gateway. The responses should reflect the configuration previously defined in the CP, including any routes, services, or plugins you have configured.
This confirms that the traffic gateway node is correctly using the fallback configuration and can continue serving traffic even when the CP is unavailable.